Abstract
Query expansion is a fundamental component of e-commerce search, yet it remains challenging in production settings due to short and ambiguous user queries, incomplete historical supervision, and constantly evolving product catalogs. Traditional expansion methods based on semantic similarity or few-shot prompting fail to capture domain-specific constraints, while existing reinforcement learning approaches often optimize for narrow objectives without interacting with real search systems. REFLEX is a catalog-grounded framework that trains a large language model through search-engine-in-the-loop reinforcement learning. It grounds reasoning in the retrieval set from the initial query and optimizes expansions with real-time search feedback using relevance alignment and retrieval breadth rewards. Experiments on large-scale industrial data show substantial gains in semantic coverage and retrieval effectiveness over strong baselines, and online A/B testing confirms production impact on relevance, diversity, and user engagement.
Method Overview
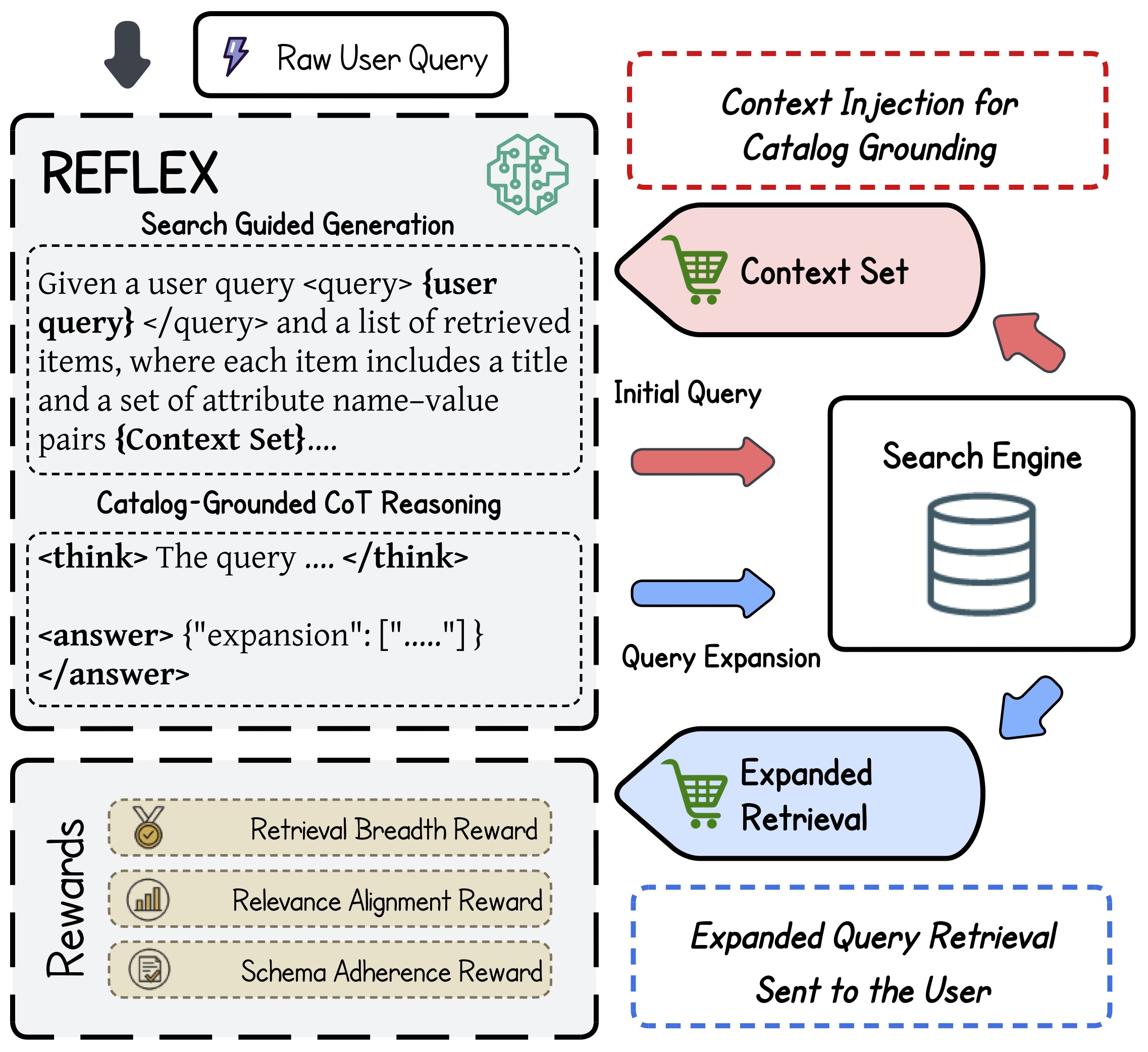
- Catalog-grounded expansion: build expansions from retrieved product context (title + attributes) to improve catalog compliance.
- Structured generation: model outputs
<think>reasoning and<answer>JSON expansions for downstream execution. - Reward design: combine relevance alignment and retrieval breadth, with schema-validity gating.
- Policy learning: optimize one-to-many expansion sets with Group Relative Policy Optimization (GRPO).
Main Results (Offline)
| Model | Backbone | ΔCoverage (%) | ΔRel (%) |
|---|---|---|---|
| EBQE | Sentence-BERT | 8.99 ± 0.00 | 26.01 ± 0.00 |
| GPT-4.1 (few-shot) | OpenAI Proprietary | 16.51 ± 2.03 | 27.82 ± 2.01 |
| SFT-LLM | LLaMA 3.2-3B | 19.22 ± 0.09 | 15.10 ± 1.40 |
| REFLEX | LLaMA 3.2-3B | 72.84 ± 3.91 | 32.40 ± 4.37 |
Ablation Study
| WarmUp | GRPO | Backbone | ΔCoverage (%) | ΔRel (%) |
|---|---|---|---|---|
| No | No | LLaMA 3.2-3B | 12.80 ± 0.50 | 8.93 ± 0.40 |
| No | Yes | LLaMA 3.2-3B | 57.45 ± 4.00 | 25.20 ± 5.00 |
| Yes | Yes | LLaMA 3.2-1B | 29.41 ± 2.28 | 14.50 ± 1.13 |
| Yes | Yes | LLaMA 3.2-3B | 72.84 ± 3.91 | 32.40 ± 4.37 |
| Yes | Yes | LLaMA 3.1-8B | 76.00 ± 3.80 | 34.00 ± 3.90 |
Online Evaluation
In a two-week production A/B test (10% traffic control vs 10% traffic treatment), REFLEX served cached expansions for roughly 600K high-frequency queries under latency constraints. The treatment group achieved statistically significant gains in click-through rate and reduced query abandonment, with consistent positive impact through the conversion funnel and measurable improvement in gross merchandise value (exact lift values are confidential).
Ethical Considerations
REFLEX mitigates online privacy and adversarial risks by serving only pre-vetted, offline cached expansions in production. Governance focuses on fairness auditing (avoiding seller favoritism), integration with platform safety filters, and versioned cache updates with monitoring, rollback, and human review for sensitive categories.
Citation
@inproceedings{zhang2026reflex,
title = {REFLEX: Reinforcement Feedback Learning with Large Language Models for E-commerce Query Expansion},
author = {Zhang, Yipeng and Liu, Bowen and Zhang, Xiaoshuang and Mandal, Aritra and Xu, Canran and Wu, Zhe},
booktitle = {Proceedings of the ACM International Conference on Web Search and Data Mining (WSDM)},
year = {2026},
doi = {10.1145/3773966.3779381}
}